
forDevLife
Springboot의 Connection Pool 본문
해당 글은 WAS의 커넥션, 스레드 풀에 대해서 정리하였습니다.
1. 커넥션 풀? 스레드 풀?
MySQL에서 사용자 요청을 처리하는 포그라운드(foreground) 스레드에 대해서 학습하다가, 커뮤니티 버전과 엔터프라이즈 버전에서 MySQL 서버의 스레드가 사용자 요청 connection을 다르게 처리한다는 것을 알게 되었습니다.
그 과정에서 커넥션 풀, 스레드 풀의 용어가 나오는데 이게 우리가 개발하는 애플리케이션에 포함되는건지 MySQL 서버에 포함되는건지 헷갈려서 정리하게 되었습니다. 결론부터 얘기하면 다음과 같습니다.
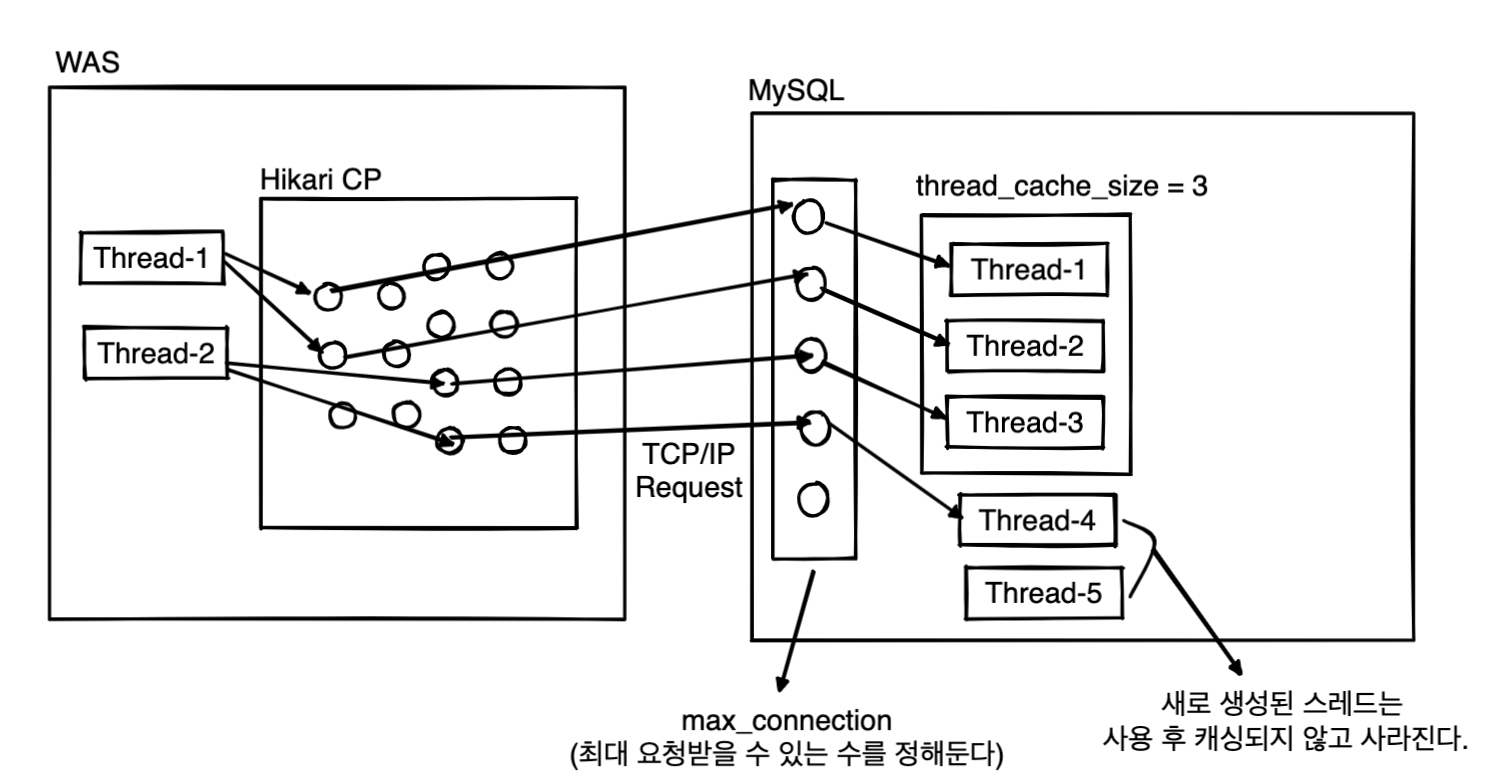
- 커넥션 풀 : WAS에서 관리(Hikari CP)
- 스레드(풀) : 각각 관리
- WAS : ExecutorService를 사용한 스레드 관리
- MySQL : 스레드 캐시(커뮤니티 ver) 또는 스레드 풀(엔터프라이즈 ver) 사용
connection은 실질적으로 Client(요청을 보내는 쪽-WAS)에서 관리하게 되며, MySQL 서버에서는 최대 요청받을 수 있는 connection 수만 정해놓게 됩니다. 이를 통해 Client에서 커넥션을 생성하고 해제하지 않거나 과도한 커넥션을 요청하는 등 MySQL 서버에도 부하를 줄 수 있는 case 들을 제어할 수 있게 됩니다.
MySQL 서버쪽의 Thread를 깊게 파보기에는 어려움이 있어서 버전 별 처리 방식에 대해서만 간단하게 알아보고 넘어가겠습니다.
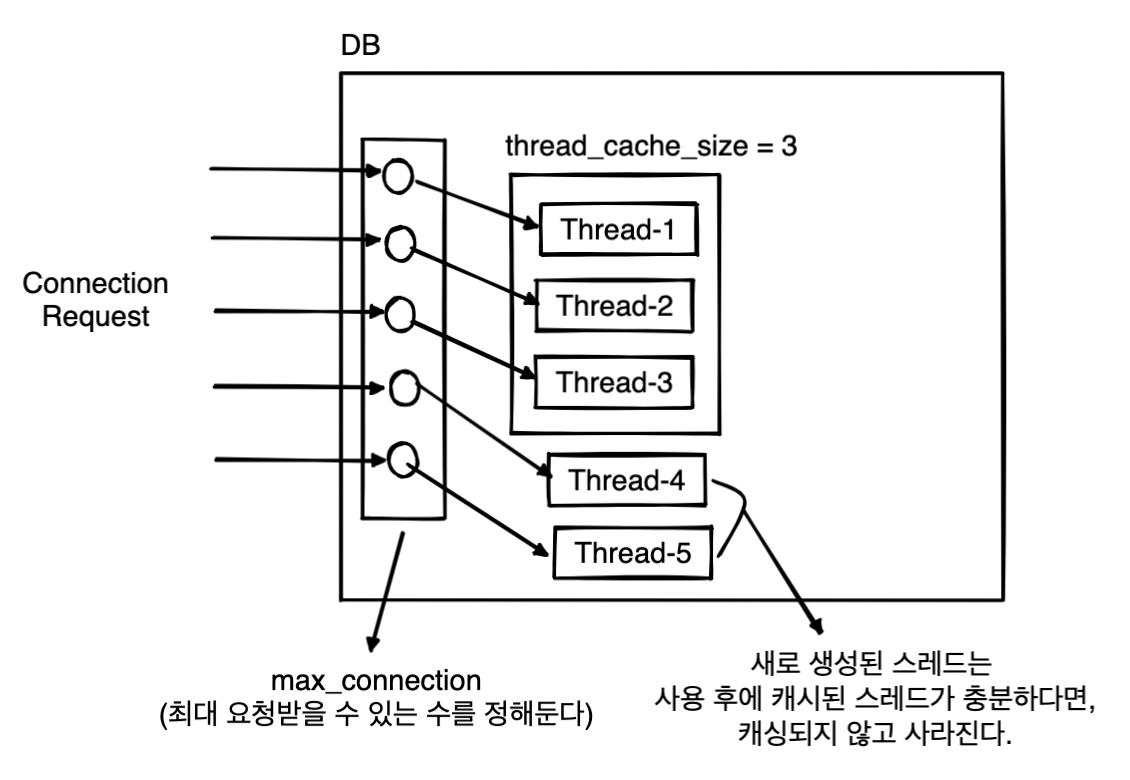
커뮤니티 버전 : 커넥션 당 스레드가 하나씩 할당(one-thread-per-connection)
MySQL 서버에서는 연결 스레드 할당으로 인한 리소스 낭비 및 성능 저하를 막기 위해 특정 개수의 스레드를 메모리에 캐싱해서 사용한다. 이를 통해 연결로 발생하는 오버헤드를 줄일 수 있으며, 클라이언트 커넥션 요청과 (포그라운드)스레드가 1:1로 매핑된다.
엔터프라이즈 버전 : 하나의 스레드가 여러 커넥션을 담당(Pool-of-threads : 스레드 풀 사용)
내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많다 하더라도 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있도록 하여 서버의 자원 소모를 줄이는 것이 관건이다. 기본적으로 CPU core의 개수만큼 스레드 그룹을 생성하여 CPU의 프로세스 친화도를 높이고, 운영체제 입장에서는 불필요한 컨텍스트 스위치를 줄여 오버헤드를 낮출 수 있다.
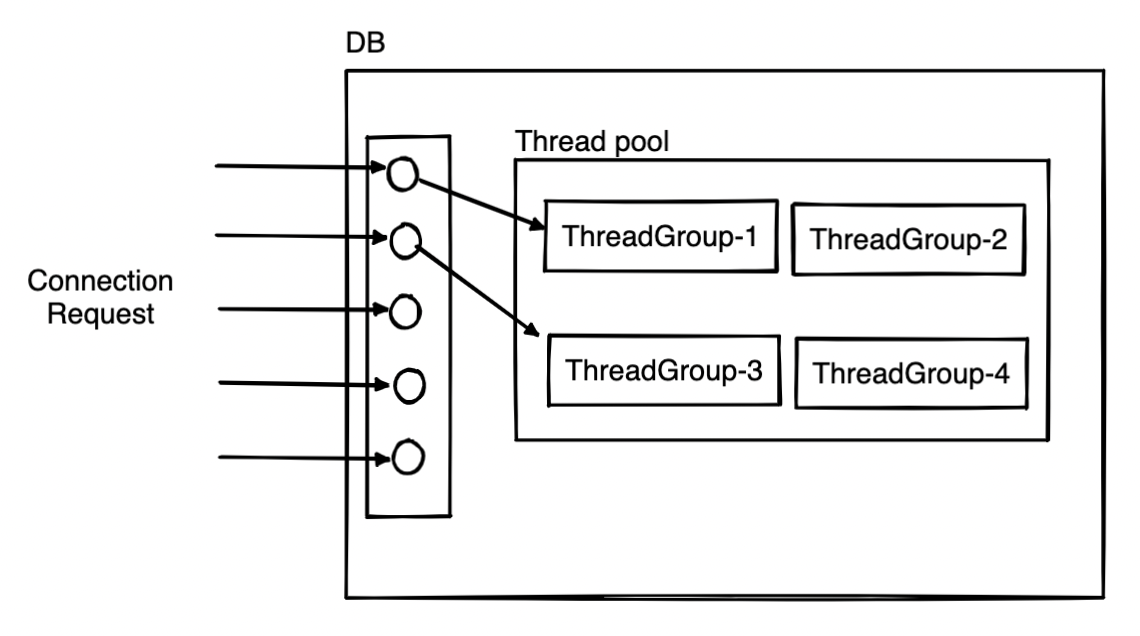
스레드 풀에 대한 설명이 조금 부족하지만, 특정 트랜잭션이나 쿼리를 우선적으로 처리할 수 있는 우선순위 큐를 사용한다는 것으로 보아 스레드가 커넥션 자체에 의존하지 않고 Task(트랜잭션, 쿼리) 단위로 처리한다고 이해했습니다. (추후 더 학습 후 보강하도록 하겠습니다.)
※ 커뮤니티 버전에서도 thread_cache_size를 통한 튜닝이 가능하기 때문에 어느정도 시스템 안정성을 보장할 수 있습니다.
2. DBCP, DataSource, ExecutorService
그럼 WAS에서의 커넥션 풀이 어떻게 관리되는지, 그리고 사용되는 스레드 풀들이 어떤게 있는지 알아보기 전 이를 이해하기 위해 필요한 개념인 DBCP, DataSource, ExecutorService에 대해서 먼저 알아보도록 하겠습니다.
1) DBCP(Database Connection Pool)
서버가 DB에 접속하기 위해 생성하는 connection은 3-way-handshaking이 발생한다는 점에서 큰 비용이 드는 작업임을 알 수 있습니다. DB Connection 객체를 미리 만들어 Connection Pool에 보관하고 필요할 때마다 DB에 연결된 Connection을 꺼내 사용할 수 있도록 하는 방식이 DBCP이며, 재사용하는 방법으로 CPU의 부담과 객체 생성, 시간을 줄일 수 있도록 합니다.
간단하게 커넥션 풀을 구현해보도록 하겠습니다.
import java.sql.Connection;
public interface ConnectionPool {
Connection getConnection();
boolean releaseConnection(Connection connection);
}
DriverManager를 사용해서 커넥션을 직접 생성하고, List에 담는 방식으로 간단히 구현해볼 수 있습니다.
SIZE를 고정시키기 위해 정적 팩토리 메서드로 커넥션 풀을 생성하도록 구현하였습니다.
public class BasicConnectionPool implements ConnectionPool {
private String url;
private String user;
private String password;
private List<Connection> connectionPool;
private List<Connection> usedConnections = new ArrayList<>();
private static int INITIAL_POOL_SIZE = 10;
private BasicConnectionPool(String url, String user, String password, List<Connection> connectionPool) {
this.url = url;
this.user = user;
this.password = password;
this.connectionPool = connectionPool;
}
public static BasicConnectionPool create(
String url, String user, String password) throws SQLException {
List<Connection> pool = new ArrayList<>(INITIAL_POOL_SIZE);
for (int i = 0; i < INITIAL_POOL_SIZE; i++) {
pool.add(createConnection(url, user, password));
}
return new BasicConnectionPool(url, user, password, pool);
}
private static Connection createConnection(String url, String user, String password) throws SQLException {
return DriverManager.getConnection(url, user, password);
}
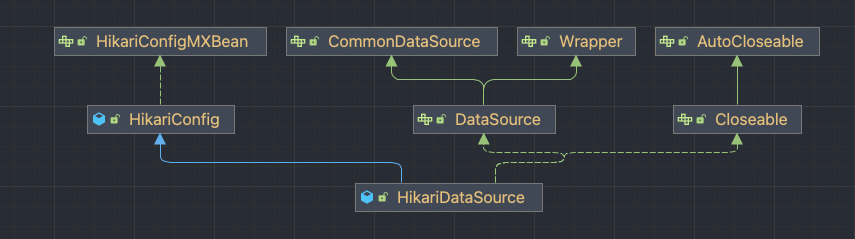
2) DataSource
서로 다른 DBCP 구현체가 많아지게 되어 (더 효율적인)다른 구현체로의 변경이 어려워지는 문제가 발생하였습니다. 이러한 문제를 해소하기 위해 DBCP 표준 인터페이스를 만들었으며, 이것이 DataSource입니다.
SpringBoot2.0 기준으로 HikariDataSource가 Default Connection Pool입니다.
3) ExecutorService
자바에서 제공하는 스레드 풀 인터페이스이며, 병렬 작업 시 여러 개의 작업을 효율적으로 처리할 수 있도록 제공되며, Executors를 이용해 ExecutorService의 구현체들을 생성할 수 있습니다. 알아볼 구현체는 다음과 같습니다.
- ThreadPoolExecutor : 기본적인 스레드 풀 구현체이며, 생성 시 다음 인자를 전달받습니다.
- corePoolSize : 풀의 기본 사이즈를 지정합니다(기본 몇 개의 스레드를 가질지).
- maximumPoolSize : 스레드 풀의 max size이며, 이 사이즈를 넘어가면 RejectExecutionException이 발생하게 됩니다.
- keepAliveTime : idle 스레드의 alive time이며, 이 시간 후에 idle 스레드가 제거됩니다.
- workQueue : 스레드가 실행하기 위한 task를 Queueing하는 역할을 합니다.
- ScheduledExecutorService : '일정 시간 후' 또는 '주기적'으로 task를 실행시켜주는 스레드 풀 구현체입니다.
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)
: 처음에는 initialDelay 후 command를 실행시킵니다. 초기 작업이 끝난시간 + delay 후에 다시 command가 실행됩니다.
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)
@Component
public class ThreadPoolConfig {
private static final Logger log = LoggerFactory.getLogger(ThreadPoolConfig.class);
public ThreadPoolConfig() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleWithFixedDelay(new HouseKeeper(), 2000, 3000, TimeUnit.MILLISECONDS);
}
private static final class HouseKeeper implements Runnable {
@Override
public void run() {
log.info("houseKeeper is called");
}
}
}// 3초 간격으로 실행되는 것을 확인할 수 있습니다.
2022-05-20 10:09:33.010 INFO 6960 --- [pool-1-thread-1] hello.login.threadPool.ThreadPoolConfig : houseKeeper is called
2022-05-20 10:09:36.018 INFO 6960 --- [pool-1-thread-1] hello.login.threadPool.ThreadPoolConfig : houseKeeper is called
2022-05-20 10:09:39.024 INFO 6960 --- [pool-1-thread-1] hello.login.threadPool.ThreadPoolConfig : houseKeeper is called
2022-05-20 10:09:42.026 INFO 6960 --- [pool-1-thread-1] hello.login.threadPool.ThreadPoolConfig : houseKeeper is called
3. WAS에서의 커넥션, 스레드 풀 관리
앞서 알아본 것처럼 HikariDataSource는 DataSource의 구현체이며, 실질적인 Connection은 내부 HikariPool에서 관리합니다.
public final class HikariPool {
{
private final ConcurrentBag<PoolEntry> connectionBag;
private final PoolEntryCreator poolEntryCreator = new PoolEntryCreator(null /*logging prefix*/);
private final PoolEntryCreator postFillPoolEntryCreator = new PoolEntryCreator("After adding ");
private final ThreadPoolExecutor addConnectionExecutor;
private final ThreadPoolExecutor closeConnectionExecutor;
private final ScheduledExecutorService houseKeepingExecutorService;
private ScheduledFuture<?> houseKeeperTask;
// ..PoolEntry
HikariPool에서는 Connection 객체를 한번 wrapping한 PoolEntry 객체로 Connection을 관리하게 되는데, 이를 통해 ConcurrentBag에서 Connection 인스턴스를 추적할 수 있게 됩니다.
ConcurrentBag<PoolEntry>
PoolEntry(커넥션을 담고 있는 객체)를 관리하며, 스레드에게 커넥션을 빌려주고 회수하는 역할을 합니다.
PoolEntryCreator
둘 다 Callable<Boolean>이며, 설정된 Config 조건에 따라서 PoolEntry를 만들고 ConnectionBag에 add해주는 call 메서드가 구현되어 있습니다. 성공 시 true, 아니면 false를 반환하며, 스레드 풀에 할당될 task가 됩니다.
먼저 HikariPoold의 생성자를 보면, 앞서 살펴본 ScheduledExecutorService를 통해 HouseKeeper라는 Runnable 구현체를 일정시간을 두고 반복 실행하도록 할당하는 부분을 확인할 수 있습니다.
this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
HouseKeeper는 내부 run()에서 fillPool() 메서드를 실행하게 됩니다.
private synchronized void fillPool()
{
final int connectionsToAdd = Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections())
- addConnectionQueueReadOnlyView.size();
if (connectionsToAdd <= 0) logger.debug("{} - Fill pool skipped, pool is at sufficient level.", poolName);
for (int i = 0; i < connectionsToAdd; i++) {
addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator);
}
}앞서 PoolEntryCreator(poolEntryCreator, postFillPoolEntryCreator)는 PoolEntry를 만들어 connectionBag에 add하는 Callable 객체라고 설명하였습니다. 이 과정을 통해 HikariPool은 반복적으로 connection 개수를 확인하여, connectionToAdd > 0일 경우에 PoolEntry를 add하는 방식으로 minumum idle connection을 유지하는구나!라고 추측할 수 있게 됩니다.
이제 이 커넥션이 어떻게 할당되는지 HikariPool의 getConnection()을 살펴보겠습니다.
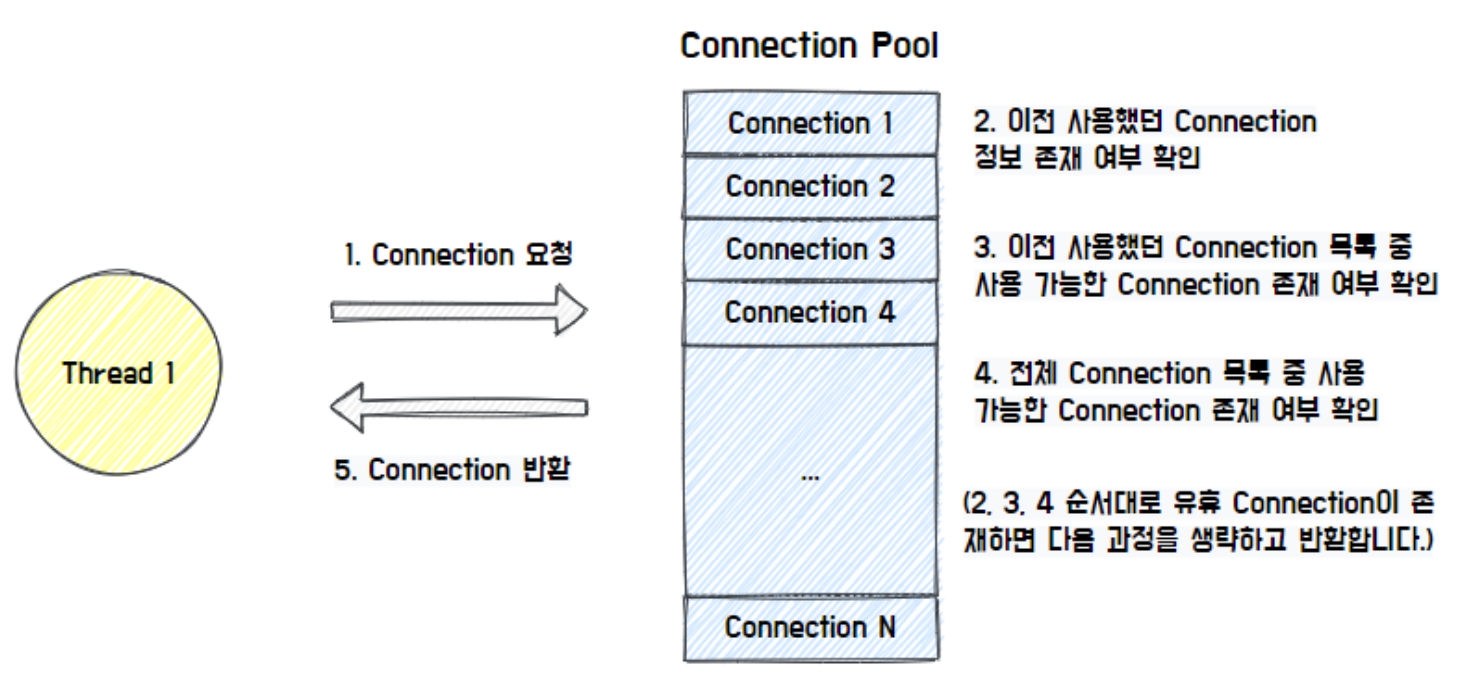
전체적인 Connection Pool에서 커넥션을 가져오는 흐름은 다음과 같습니다.
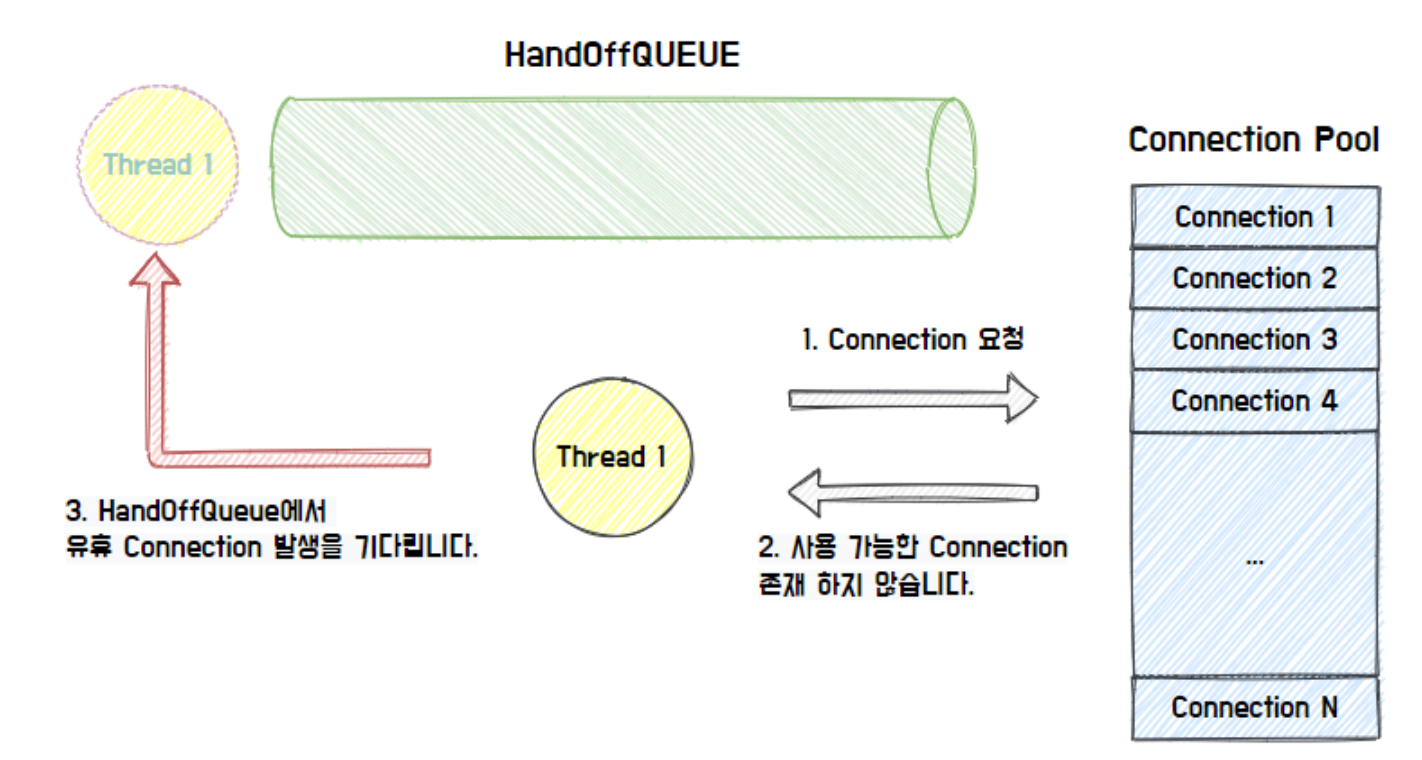
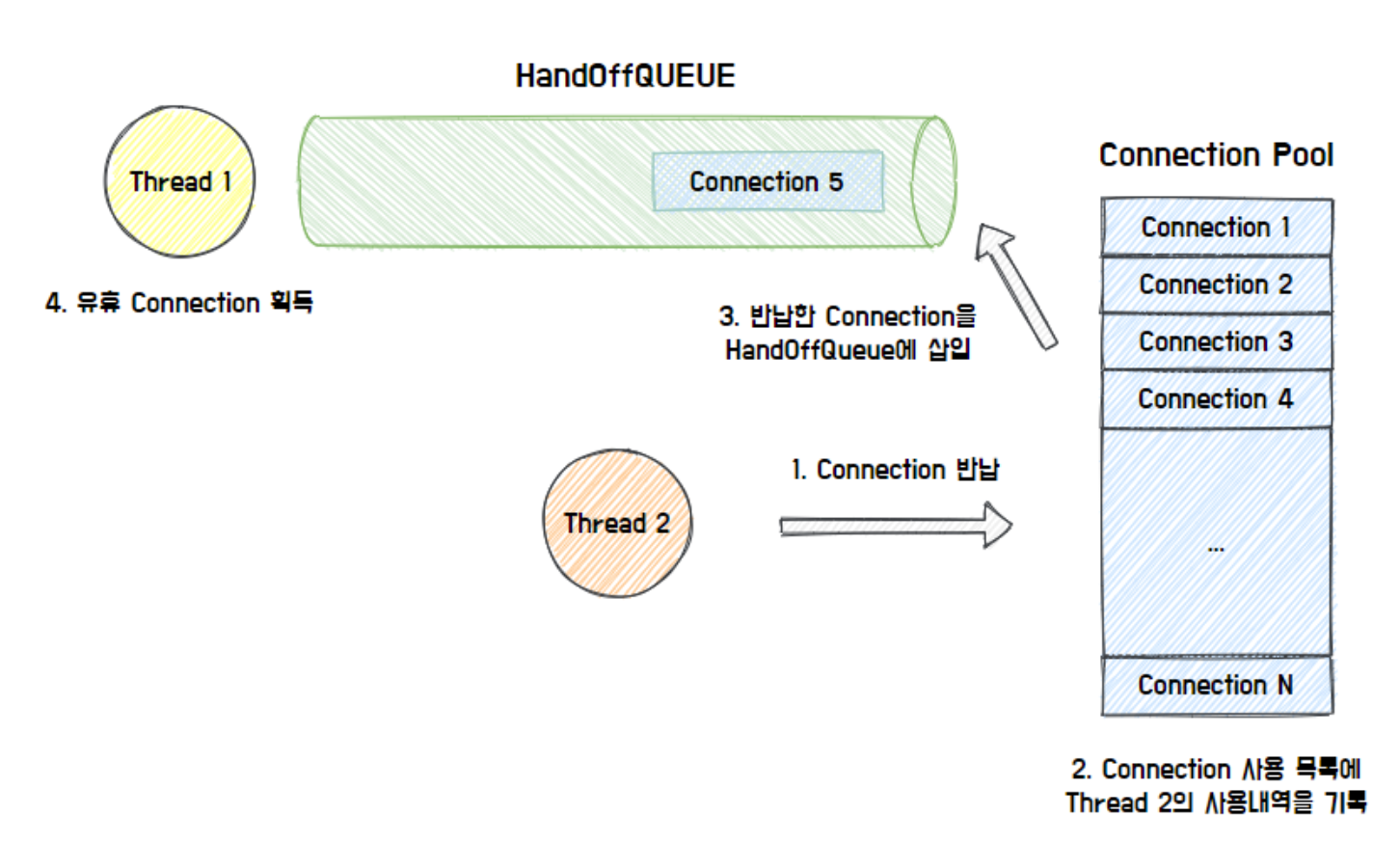
참고
Spring Boot - 스케줄러 사용해보기 1. FixedDelay vs FixedRate
들어가며 최근에 있었던 일입니다. 제가 만든 컴포넌트를 코드 리뷰를 통해 팀원들과 공유하는 자리를 가졌었는데, 스케줄링 된 작업에 대해서 이런 질문이 들어왔었습니다. 어라.. 저 작업이 0.
seolin.tistory.com
내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 3편(DB Connection Pool)
개요 지난 시간 현재 AGORA 서비스의 단일 피드 조회 기능에 대한 성능 테스트를 진행해보았습니다. 이번 시간에는 데이터베이스의 Connection Pool의 크기를 조절해보면서 발생하는 성능 변화에 대
hyuntaeknote.tistory.com
'Spring' 카테고리의 다른 글
| JUnit5 Extension (2) | 2022.07.24 |
|---|---|
| JPA 사용 시 Entity에 기본 생성자가 필요한 이유 (0) | 2022.05.13 |
| 스프링 입문 - 웹 개발 기초 <4> (0) | 2021.05.24 |
| 스프링 입문 - 웹 개발 기초 <3> (0) | 2021.05.20 |
| 스프링 입문 - 웹 개발 기초 <2> (0) | 2021.05.18 |



